Database Concepts

The limitations of a file-based approach
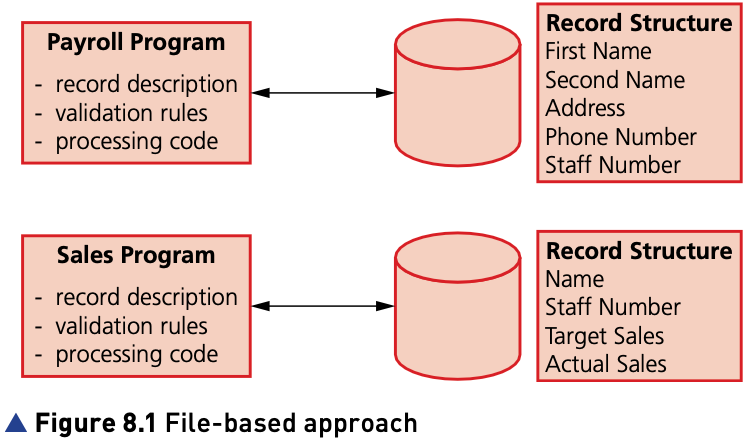
- A file is a collection of items of data.
- It can be structured as a collection of records, where each record is made up of fields containing data about the same ‘thing’.
- A file-based approach is limited because
- storage space is wasted when data items are duplicated by the separate applications and some data is redundant
- data can be altered by one application and not by another; it then becomes inconsistent
- enquiries available can depend on the structure of the data and the software used so the data is not independent.
Database
A file-based approach is limited because
The advantages of a relational database over a file-based approach
- A database is a structured collection of items of data that can be accessed by different applications programs.
- Data stored in databases is structured as a collection of records, where each record is made up of fields containing data about the same ‘thing’.
- A relational database is a database in which the data items are linked by internal pointers.
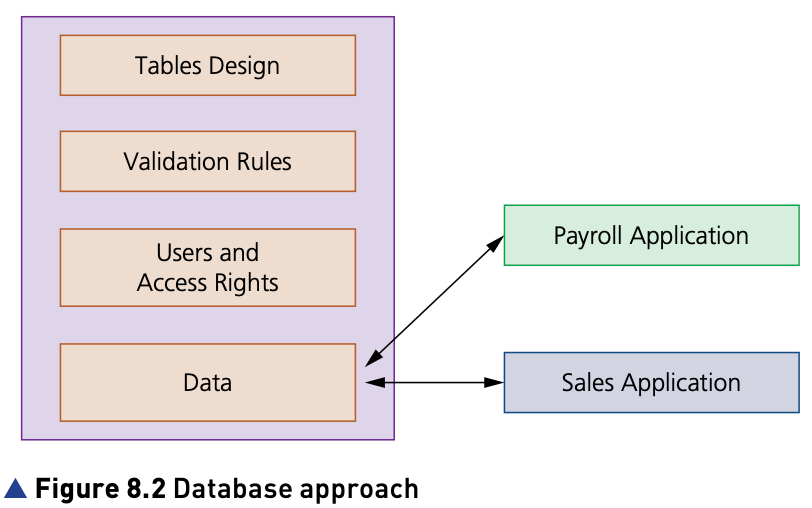
The problems that occurred using the file-based approach have been solved.
The name of a member of staff and their staff number are only stored once.
So, any changes made to the data by the payroll application will be seen by the sales processing application and vice versa. The fields are the same and in the same order.
A database approach is beneficial because
- storage space is not wasted as data items are only stored once, meaning little or no redundant data
- data altered in one application is available in another application, so the data is consistent
- enquiries available are not dependent on the structure of the data and the software used, so the data is independent.
Database
A database approach is beneficial because
Relational database model terminology
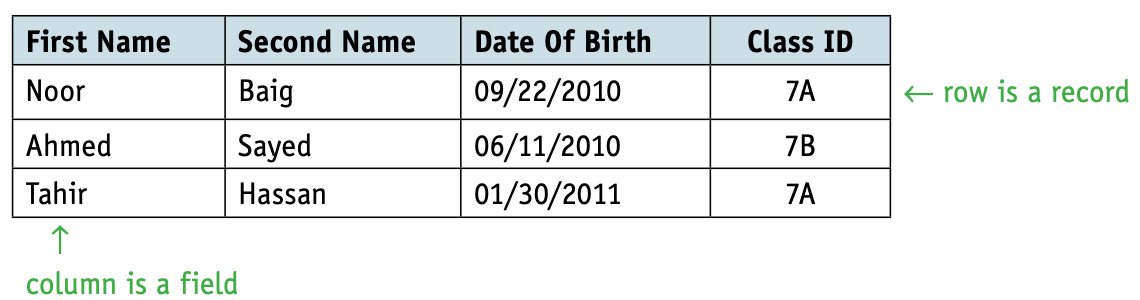
A relational database data structure can look similar to a file-based structure as it also consists of records and fields.
- A table is a group of similar data, in a database, with rows for each instance of an entity and columns for each attribute.
- A record is a row in a table in a database.
- A field is a column in a table in a database.
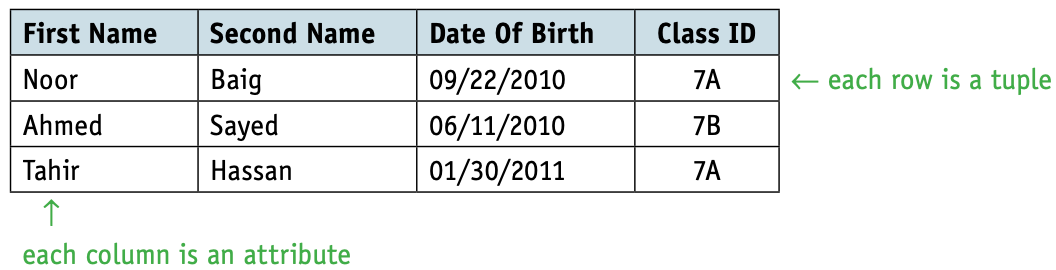
- Files of data are replaced by tables, with each row of a table representing a record (a tuple, sometimes called a logical record or an occurrence of an entity).
- Each column of the table is an attribute that can also be referred to as a field.
Database
A is a column in a table in a database
Key
- In order to reduce the number of copies of a data item to a minimum, a relational database uses pointers between tables.
- These pointers are keys that provide relationships between tables.
- There are different types of keys.
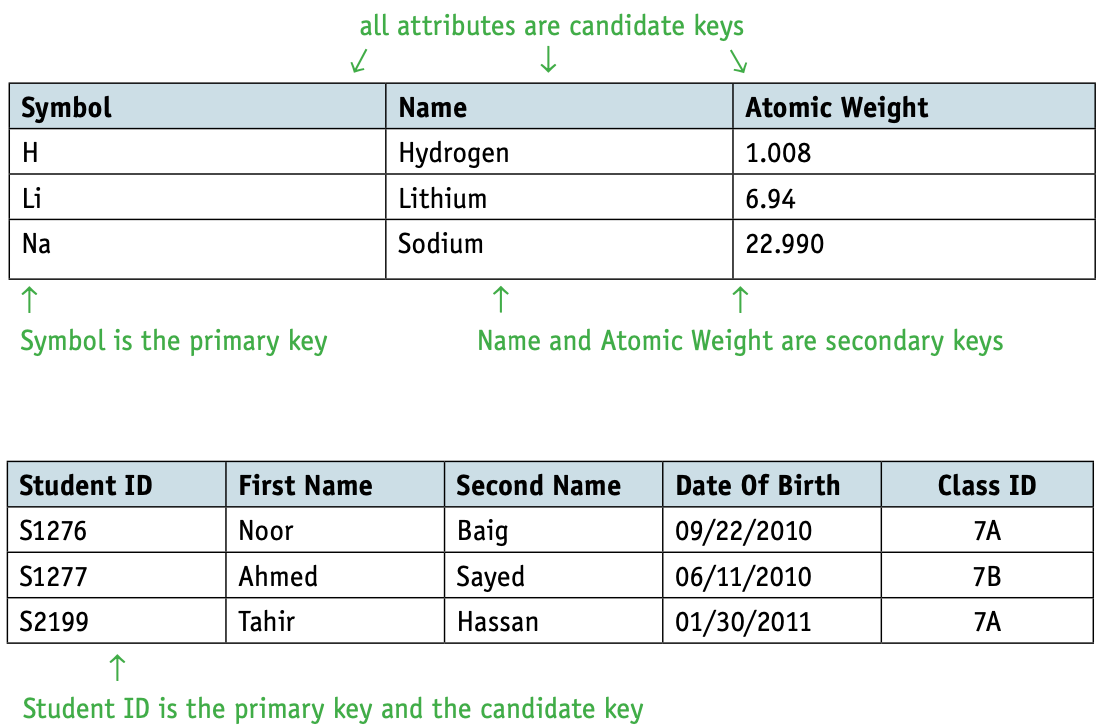
- A candidate key is an attribute or smallest set of attributes in a table where no tuple has the same value.
- A primary key is a unique identifier for a table, it is a special case of a candidate key.
- A secondary key is a candidate key that is an alternative to the primary key.
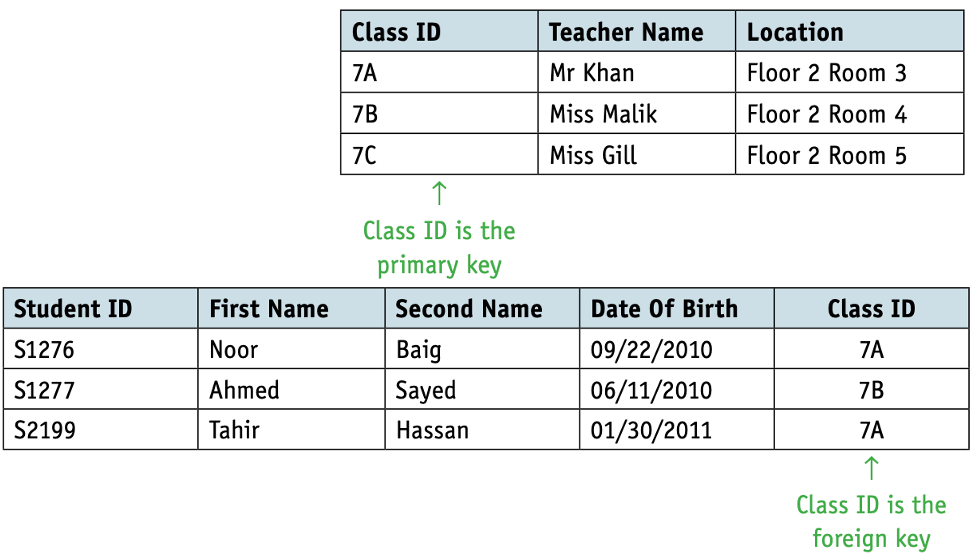
- A foreign key is a set of attributes in one table that refer to the primary key in another table.
Database
A is a unique identifier for a table, it is a special case of a candidate key
Relationship
A relationship is formed when one table in a database has a foreign key that refers to a primary key in another table in the database. In order to ensure referential integrity the database must not contain any values of a foreign key that are not matched to the corresponding primary key.
Relationships can take several forms:
- one-to-one, 1:1
- one-to-many, 1:m
- many-to-one, m:1
- many-to-many, m:m
Database
A is formed when one table in a database has a foreign key that refers to a primary key in another table in the database
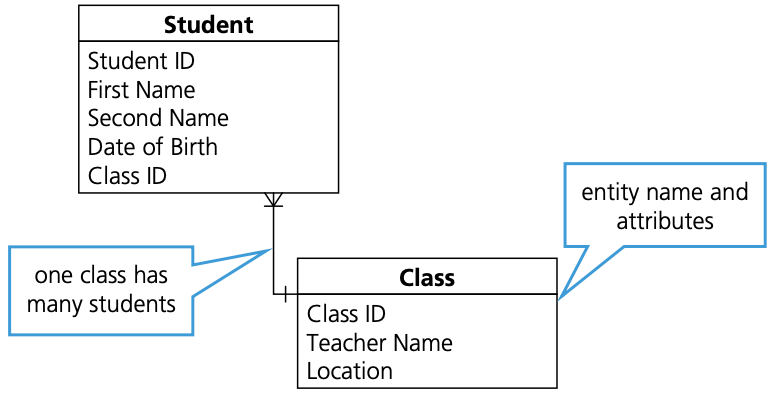
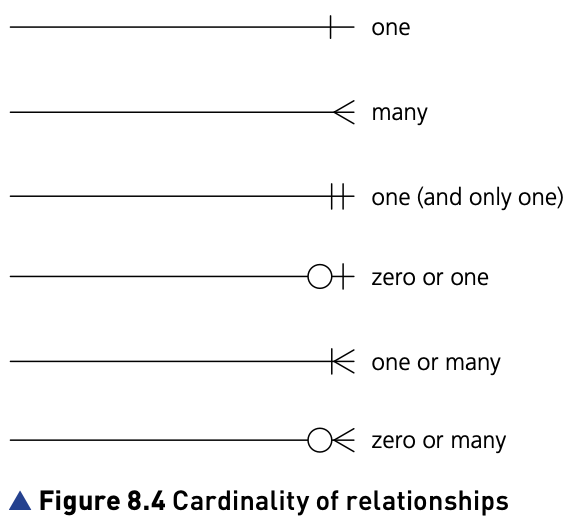
Entity-relationship (E-R) diagrams
- An E-R diagram can be used to document the design of a database.
- This provides an easily understandable visual representation of how the entities in a database are related.
Database
An can be used to document the design of a database
The normalisation process
Normalisation is used to construct a relational database that has integrity and in which data redundancy is reduced. Tables that are not normalised will be larger.
The rules for normalisation are set out as follows:
- First normal form (1NF) – entities do not contain repeated groups of attributes.
- Second normal form (2NF) – entities are in 1NF and any non-key attributes depend upon the primary key. There are no partial dependencies.
- Third normal form (3NF) – entities are in 2NF and all non-key attributes are independent. The table contains no non-key dependencies.
First normal form (1NF)
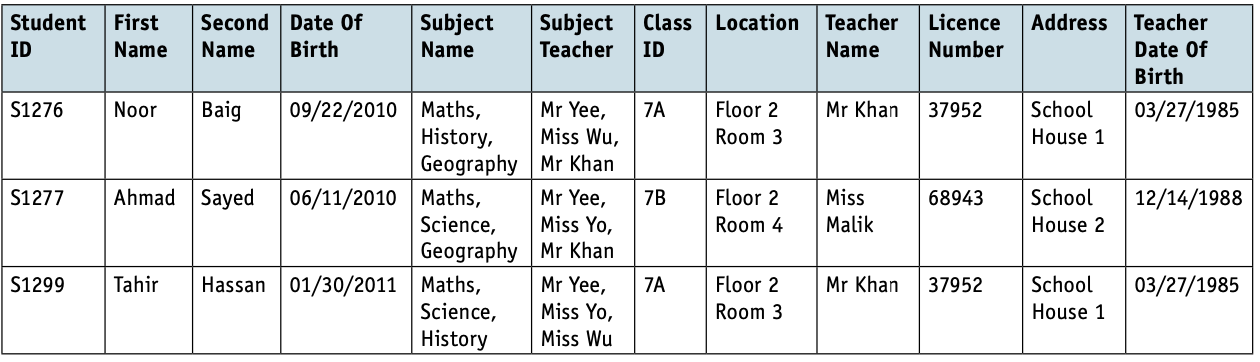
- The School database can now be represented in 1NF as follows.
STUDENT(StudentID, FirstName, SecondName, DateOfBirth, ClassID, Location, TeacherName, LicenceNumber, Address, TeacherDateOfBirth).
STUDENTSUBJECT(StudentID, SubjectName, SubjectTeacher).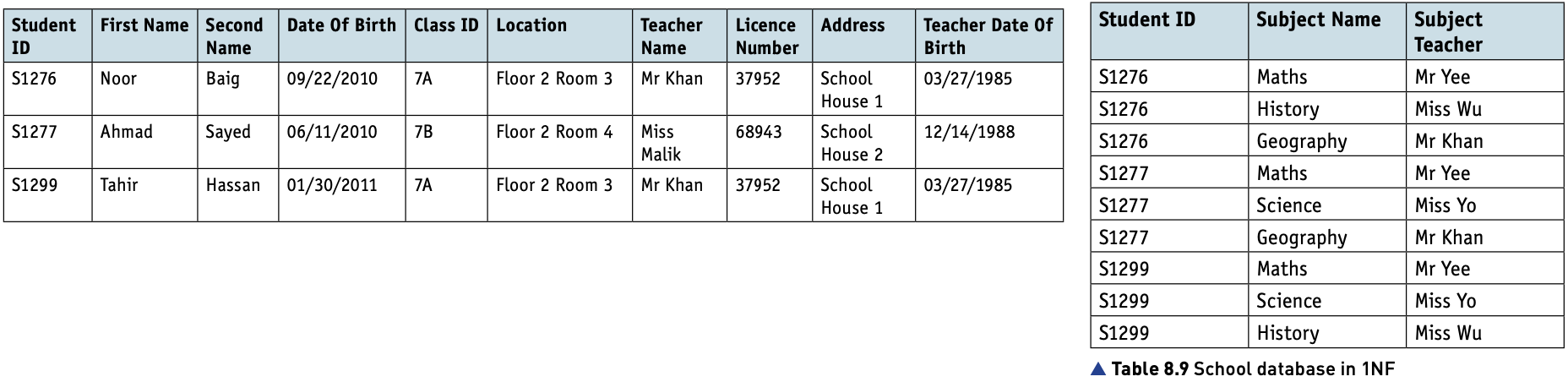
Second normal form (2NF)
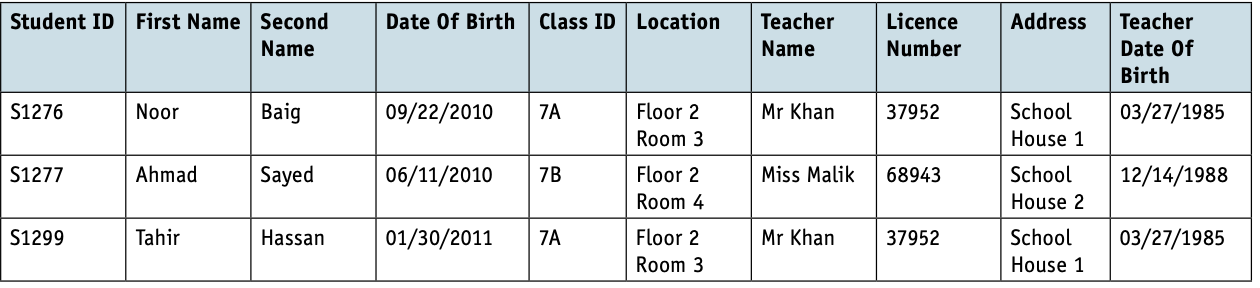
The School database can now be represented in 2NF as follows.
STUDENT(StudentID, FirstName, SecondName, DateOfBirth, ClassID, Location, TeacherName, LicenceNumber, Address, TeacherDateOfBirth)
STUDENTSUBJECT(StudentID, SubjectName)
SUBJECT(SubjectName, SubjectTeacher)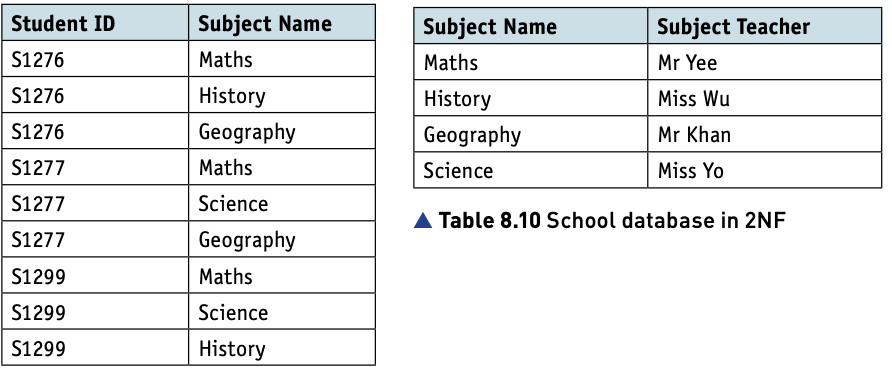
Third normal form (3NF)
The improved School database can now be represented in 3NF as follows.
STUDENT(StudentID, FirstName, SecondName, DateOfBirth,)
CLASS(ClassID, Location, LicenceNumber)
TEACHER(LicenceNumber, TeacherName, Address, TeacherDateOfBirth)
STUDENTSUBJECT(StudentID, SubjectName)
SUBJECT(SubjectName, LicenceNumber)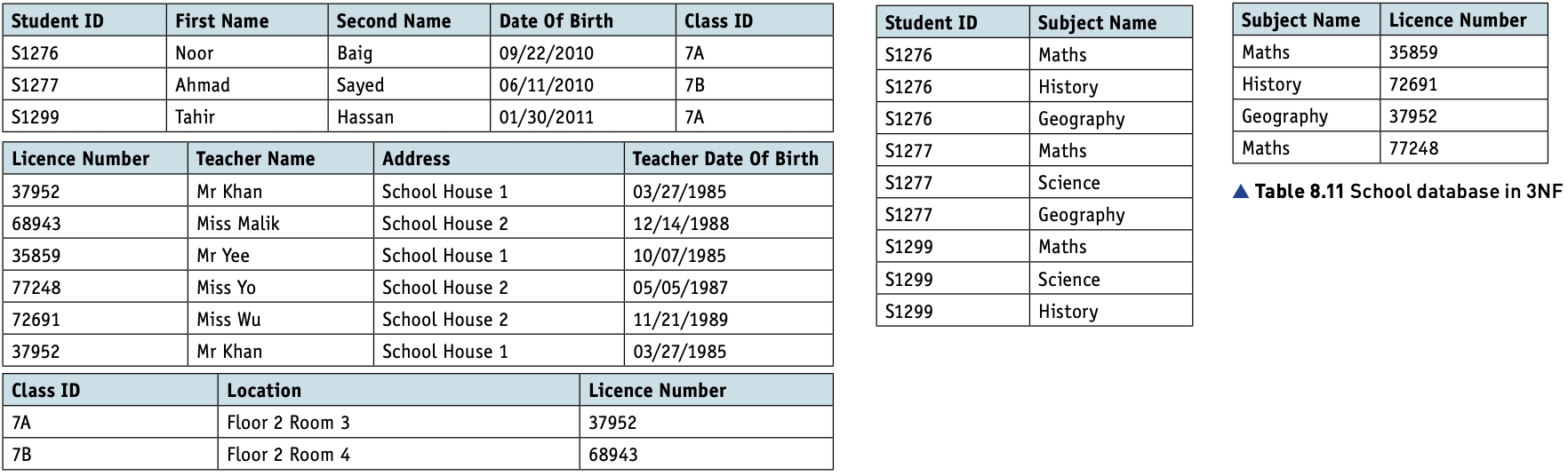
Student
| ID | FirstName | LastName | Age | ClassID |
|---|---|---|---|---|
| 1 | Jack | Smith | 10 | 1 |
| 2 | Tom | Bush | 11 | 2 |
| 3 | Tina | White | 11 | 2 |
Class
| ID | Name |
|---|---|
| 1 | C1 |
| 2 | C2 |
Teacher
| ID | FirstName | LastName | Age |
|---|---|---|---|
| 1 | John | Brown | 30 |
| 2 | Jack | Jones | 31 |
TeacherClass
| ClassID | TeacherID |
|---|---|
| 1 | 1 |
| 2 | 2 |
Database
Entities do not contain repeated groups of attributes?